
|
| IPHOD: HOME, BLOG, DOWNLOAD, SEARCH, CALCULATOR, DETAILS, KENNY VADEN |
|
Details on IPhOD: organization and measures The IPhOD was calculated over a large word set in calculations for phonotactic probability and neighborhood density, after the approach of Vitevitch and Luce (1999). Phonotactic probabilities refer to the concurrence likelihood of some sequence of sounds that are present in a given word. Phonological neighborhood density counts the number of words that share all but one phoneme with a particular word or pseudoword. Positional probabilities refer to the average likelihood of each phoneme occurring in each position of a word. These counting and probability measures also were weighted using frequency and log frequency to reflect their occurrence in natural language. The IPhOD measures extend on definitions from Vitevitch and Luce (1999), by performing these calculations while distinguishing vowels with different syllable stress placement or not. In stressed calculations, otherwise identical vowel sounds are considered to be distinct phonemes depending on primary, secondary, or no-stress placement. The so-called unstressed calculations collapse vowel sounds into single phoneme categories. This may allow syllable stress related hypotheses to be tested, since the information was available in the transcriptions in the Carnegie-Mellon Pronouncing Dictionary (Weide, 1994). Version 2.0 versus 1.4 IPhOD version 2.0 contains phonotactic and density estimates, American English transcriptions of 1-28 phonemes, and word frequencies for 54,030 word and 814,840 pseudoword entries. Each entry contains an American English phonetic transcription from the Carnegie-Mellon Pronouncing Dictionary (Weide, 1994), and written word frequencies from the SUBLEXus database (Brysbaert & New, 2009). Neighborhood density and word averaged phoneme-sequence probabilities were extrapolated from those data using the same formulas for words and pseudowords, so that entries of either type could be chosen using identical criteria. IPhOD version 1.4 contains transcriptions of 1-17 phonemes, and word frequencies for 33,432 words and 814,840 pseudowords. Each entry contains an American English phonetic transcription from the Carnegie-Mellon Pronouncing Dictionary (Weide, 1994), and Kucera-Francis written word frequencies (1967) from the MRC Psycholinguistic Dictionary (Wilson, 1988). Additional Information about Version 2.0 Different ways of saying the same thing? IPhOD version 2.0 introduced homophones and homographs to the database. This addition required special steps to be taken to avoid double-counting pronunciations or double-weighting with written word frequencies. For each measure in the database, homophones were counted separately in weighted counts since they had different written frequencies in SUBTLEXus, because words that are pronounced identically but have different spellings and therefore different written frequencies. However, homophone entries were counted only once for raw counts, since their pronunciations are indistinct. Homographs were handled oppositely: weighted counts used only one entry since there was no way of assigning written word frequency to multiple pronunciations of the same orthographic item. Meanwhile, all of the various pronunciations of homographic entries could be counted separately for the raw count. Previous versions of IPhOD had a single pronunciation for each spelling, and did not treat homographs differently from the other words. Version 2.0: All Values by Column Number and Title:
Additional Information about Version 1.4 Words & Pseudowords: nearly identical file structure ... with 2 key differences. The database contains identically organized columns in the word and pseudoword textfiles, with TWO exceptions. First, in the Word collection, the last two columns show Kucera Francis frequencies, while pseudowords have neither values. The second difference is that the first column of the pseudoword file shows the *word that was changed to produce the pseudoword*. The pseudoword files seem confusing at first, since many people read the "word" column entry, and don't see the different MRC transcription, which is really the pseudoword, as it is pronounced. Each pseudoword was generated by changing one phoneme from a real word, so it helps to see what that word was when you're going to try to pronounce it correctly. For example, "Fox" might show up as the pseudoword "word" entry - but reading the transcription columns tells you "F AH Z", so it is pronounced "Foz". Version 1.4: Summary of Columns and Contents 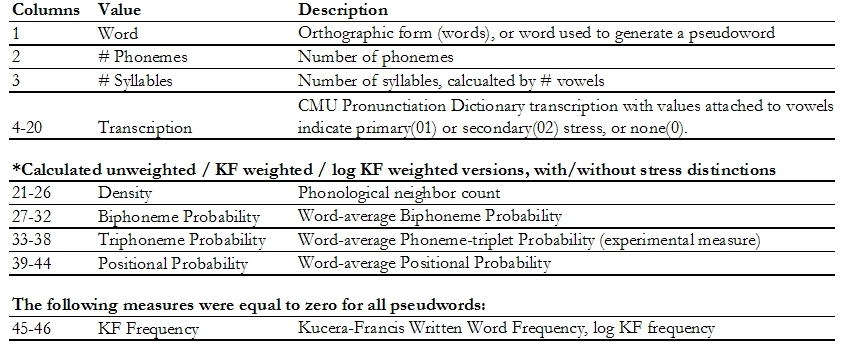
Each file of the database contains columns 1-44, and all word entries contain Kucera-Francis word frequencies (columns 45, 46). IPhOD values are used for finding items, or to quantify aspects of specified wordlists (# neighbors, etc.). Version 1.4: All Values by Column Number and Title:
|